Analytics stuck in dashboards doesn’t drive revenue; activation does. If you're sitting on clean customer data in Snowflake or BigQuery and it’s not shaping your Klaviyo flows? You’re leaking money.
This is a practical playbook for sending high-impact, warehouse to email marketing signals using reverse ETL Klaviyo integrations like Hightouch, Census, or RudderStack.
Why Warehouse→ESP Activation Wins
The modern ESP doesn’t need a full CDP to power lifecycle strategy—it just needs the right data, in the right place, at the right time.
Klaviyo is designed to work with structured inputs:
- Profile properties: long-term traits and buckets
- Custom events: behavior logs with timestamps
- Lists/Segments: the outputs that fuel personalization
Why does this matter? Because warehoused data without activation is a cost, not a driver. Once activated, it becomes the foundation of:
- Proactive win-back campaigns
- Better margin control
- Targeted loyalty treatments
But you only get compounding value if your stack respects the fundamentals:
- Consent first. Don’t risk reputation by blasting unsubscribed users.
- Identity resolution is non-negotiable. Email = key. Everything else = nice-to-have.
- Data freshness. No one wants a VIP tag based on 2022 behavior.
And no, you don’t need to license a full CDP. If your marketing and analytics teams collaborate tightly, reverse ETL gives you more control, less overhead.
Internal Link: Warehouse-Native Lifecycle Marketing (2025 Guide)
Quick Architecture (90 Seconds)
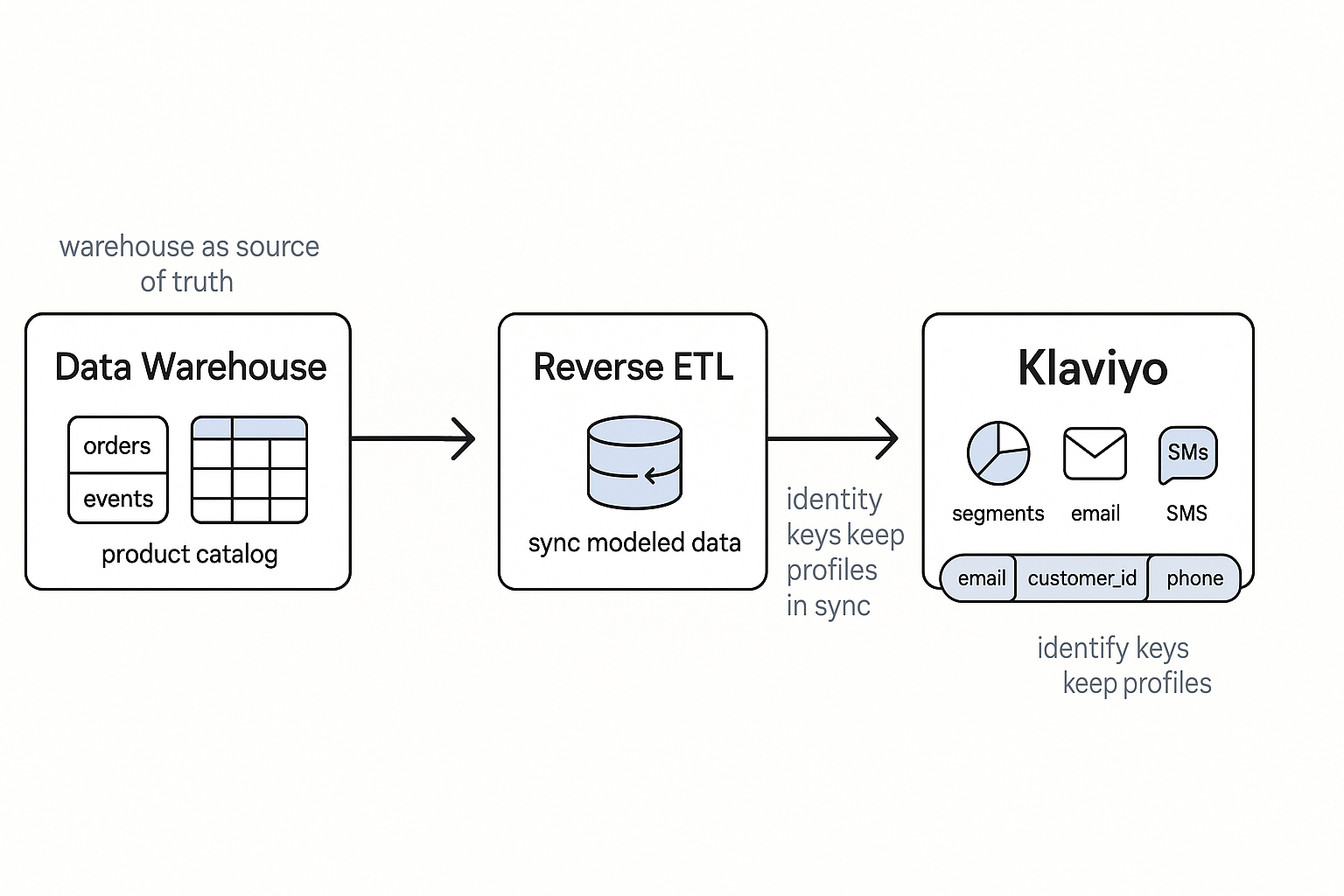
This is what a warehouse-native activation stack looks like when done right:
- Snowflake or BigQuery holds the truth
- Hightouch, Census, or RudderStack sync data
- Klaviyo consumes attributes/events in near real time
Key decisions:
- Send profile properties when the signal defines a user trait (e.g., LTV tier)
- Send events when it reflects behavior over time (e.g., viewed_product)
The golden rule: if you need it for targeting or segmentation, model it clean and push it consistently.
The Cookbook: 12 Attributes/Events to Push (with Cadence)
There are a million things you could send from your warehouse. These are the ones that actually move the needle.
Each is mapped to a business case, sync frequency, and key metric.
(Individual attribute explanations are already embedded under each entry.)
Cadence Matrix (At-a-Glance)
Timing matters. Push too often and you flood the ESP. Sync too slowly and the data's stale by the time flows fire.
Use this as your north star:
- Daily: for time-sensitive flags (churn, subscription, NPS)
- Weekly: for segments that shift gradually (AOV tier, affinity)
- Monthly: for cost-control and merchandising strategy
- Event-Driven: when real-time matters (order_created, ticket_opened)

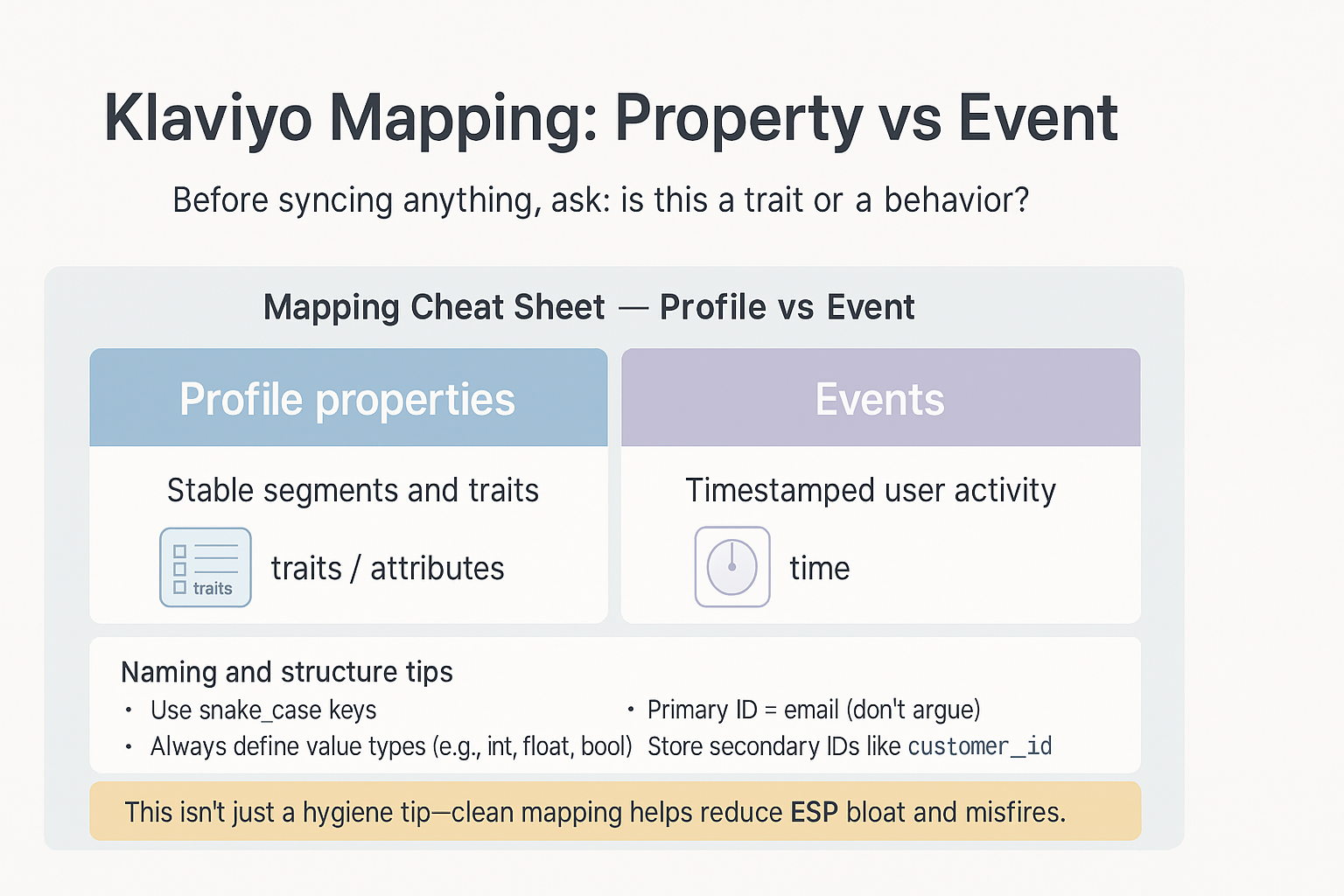
Klaviyo Mapping: Property vs Event
Before syncing anything, ask: is this a trait or a behavior?
- Profile properties = stable segments and traits
- Events = timestamped user activity
Naming and structure tips:
- Use snake_case keys
- Always define value types (e.g., int, float, bool)
- Primary ID = email (don’t argue)
- Store secondary IDs like customer_id for back joins, not logic
This isn’t just a hygiene tip—clean mapping helps reduce ESP bloat and misfires.
Example SQL / Model Notes
This part gets overlooked. But if your model breaks, so does your lifecycle.
Sample stack notes:
- BigQuery: Use RANK() OVER() and ARRAY_AGG for scores and preferences
- Snowflake: Leverage QUALIFY for clean filtering on top-N items
- dbt: Always include tests (e.g., not_null, accepted_values) to catch bad syncs before they start
You’re not just building data—you’re building infrastructure for automation. Treat it that way.
Reverse ETL Setup (Tool Notes)
Picking the right tool depends on how your team works:
- Hightouch: Ideal for marketers with light SQL. Clean UI. Real-time previews.
- Census: Deep modeling support. Best if you already live in dbt or Looker.
- RudderStack: Developer-first, with both event streaming and reverse ETL.
Sync strategy guidelines:
- Hourly for sensitive items (churn score, subscription window)
- Daily for evolving traits (AOV, affinity)
- Event-triggered for support or transaction-based flows
External Link: Hightouch Product Overview
QA & Safeguards
This is the part most teams skip—until it breaks.
Here’s your pre-launch checklist:
- Freshness validation: check for table lag > 24 hours
- Null handling: never overwrite with blanks; define defaults
- Consent rules: always sync suppression before activation
- Rollback plan: snapshot last successful sync + Slack alert if new fails
Without this? You risk syncing outdated or incorrect data that derails customer experience.
Measurement Plan: Proving Revenue Lift
This isn't a data project—it's a revenue engine. Measure it like one.
Use holdouts to isolate lift. Test by:
- Excluding certain segments from new attributes (e.g., VIP flag)
- Comparing flows with/without enhanced targeting
Track:
- Revenue per recipient
- Repeat purchase rate
- Unsubscribe rate
Overlay Klaviyo data with warehouse attribution for a complete picture.
30-Day Activation Timeline
This doesn’t need to take six months. Most teams can launch foundational attributes in under 30 days.
- Week 1: Pick 3 core traits (RFM, recency, subscription). Spec them out.
- Week 2: Model in dbt; wire reverse ETL mappings
- Week 3: QA, build flows, partial rollout
- Week 4: Go live. Monitor syncs. Track KPIs.
Start small. Prove ROI. Expand with confidence.
Common Pitfalls (and Fixes)
Avoid these and you’re already ahead of 80% of teams:
- Identity drift: Create logic to dedupe emails and enforce a canonical source
- Over-syncing noise: Push diffs only. Don’t re-send unchanged data
Stale predictions: Auto-expire scores like pLTV after N days to keep signals sharp