Choosing the right middle layer for your marketing stack isn’t about picking the flashiest tool—it’s about aligning with your data reality. This guide breaks down the tradeoffs between CDPs, Reverse ETL, and native integrations so you can choose with confidence.
This guide gives marketers a clear-eyed framework for choosing between CDPs, Reverse ETL pipelines, or native integrations. From navigating RudderStack vs Segment vs Hightouch to planning your marketing integration architecture, it's all here—stripped of fluff, stacked with tradeoffs.
Introduction — The 2025 Problem: Too Many “Middle Layers,” Not Enough Clarity
In a landscape flooded with middleware solutions, marketers face real pressure to "choose right" without overbuilding. Let’s make sense of the mess and give you a grounded way to navigate it.
Marketing teams have more options than ever—and fewer clear answers.
Do you buy a CDP? Use Reverse ETL to activate from your data warehouse for marketing? Stick with native ESP or CRM integrations?
The difference in cost alone can 10x your annual spend. Operational complexity? Same story.
This guide gives you a practical decision tree to help choose the right middle layer. Built on actual Snowflake and ESP architecture reviews. We’ll help you decide when to use a CDP, when to go warehouse-native, and when native integrations are exactly enough.
The Three Middle-Layer Options Explained
Before you decide, you need to understand what each option is actually built for. Here’s how CDPs, Reverse ETL, and native integrations stack up in the real world.
Option 1 — A Full Customer Data Platform (CDP)
Examples: Segment, RudderStack
Pros: Real-time pipelines, consent tools, identity resolution, massive integration support
Cons: Expensive, engineering-heavy, prone to underutilization
Best Fit: Large orgs doing omni-channel personalization with millions of events/month
Option 2 — Warehouse + Reverse ETL
Examples: Hightouch, Census
Pros: Custom models (AOV, churn, LTV), precise targeting, clean profile syncs
Cons: Requires data maturity (Snowflake/BigQuery, dbt, SQL fluency)
Best Fit: Teams with an analytics function that already trust the warehouse
Keyword match: cdp vs reverse etl
Option 3 — Native Integrations via ESPs, CRMs, Commerce Platforms
Examples: Klaviyo, HubSpot, Shopify, Customer.io
Pros: Cheap, fast, built-in, minimal engineering lift
Cons: Limited identity stitching, no event enrichment, low flexibility
Best Fit: Small teams with <3 tools and straightforward use cases
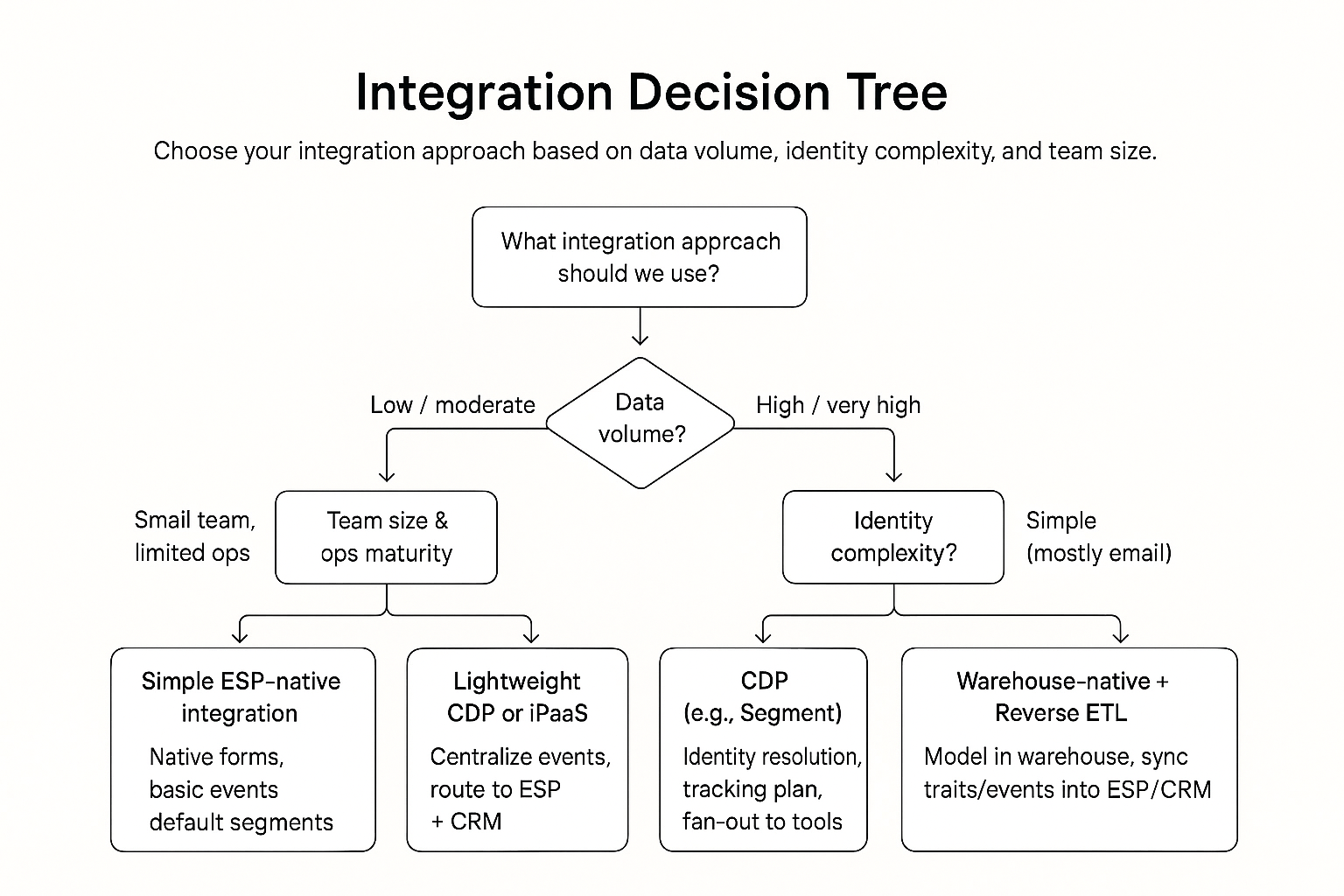
Decision Tree Overview — Pick Your Integration Strategy in 5 Minutes
Let’s take the guesswork out of the equation. Walk through five quick questions to identify your best-fit integration layer.
Step 1 — How Fragmented Is Your Data?
- 1–2 sources → Native
- 3–6 sources → Reverse ETL
- 6+ systems across teams → CDP
Step 2 — Do You Need Real-Time Events?
- <500k events/mo → Native
- 500k–5M → Reverse ETL
- 5M+ or streaming → CDP
Step 3 — Identity Resolution Requirements
- Email-only identity → Native
- Multi-touch lead scoring, device joins → Reverse ETL
- Graph-based identity (devices + emails + logins) → CDP
Step 4 — Team Skill Level (Marketing + Engineering)
- No data team → Native
- 1–2 analytics/ops leads → Reverse ETL
- Full data team/org → CDP
Step 5 — SLA Requirements (Speed, Compliance, Reliability)
- Daily batch is fine → Warehouse
- Hourly syncs needed → Reverse ETL
- Realtime under 200ms → CDP
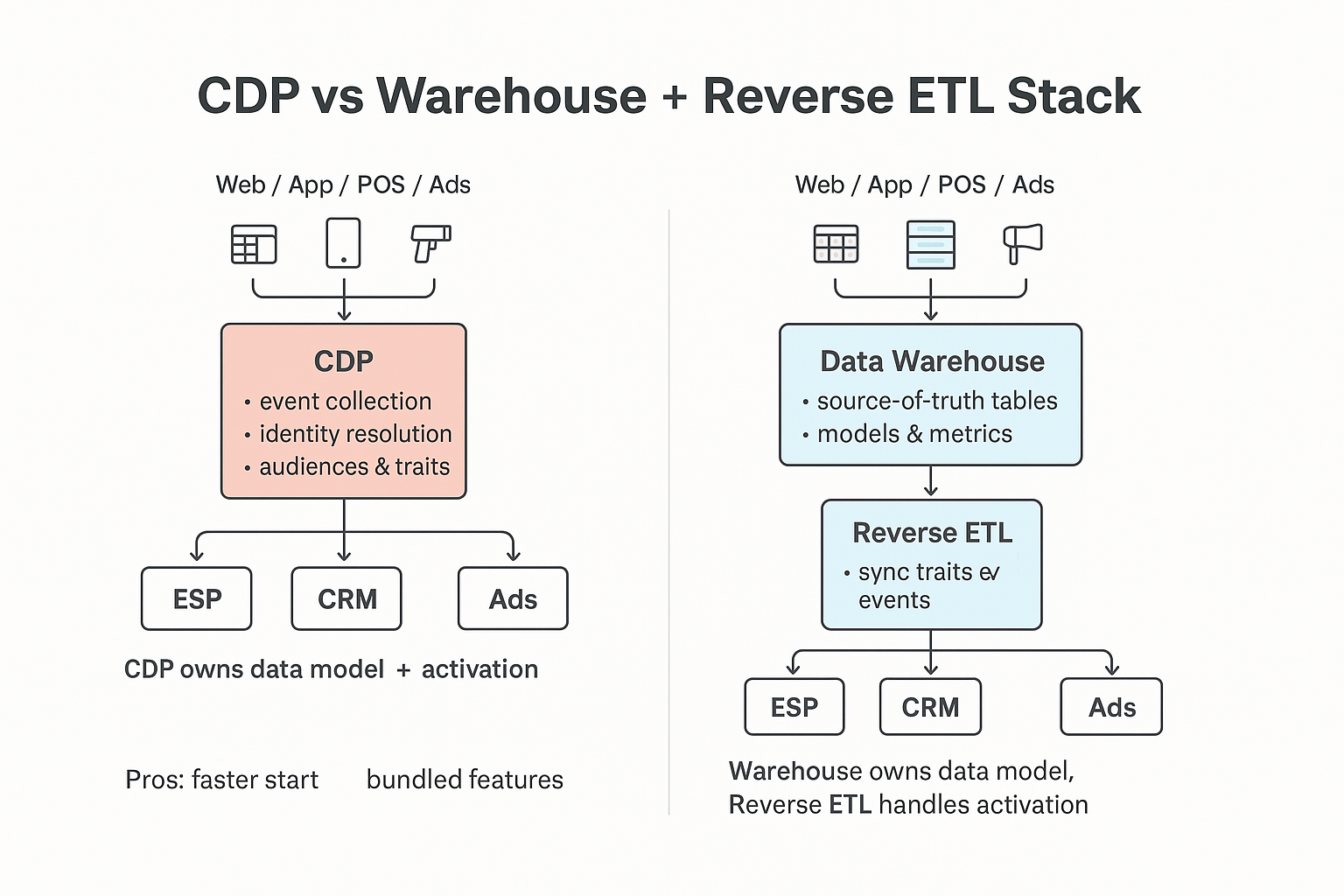
CDP vs Warehouse: The Reality Check Marketing Teams Miss
The promise of CDPs doesn’t always match up with what teams actually use. Here’s where Reverse ETL often delivers more value with less complexity.
CDPs Are Not Universal Solutions
They sound great on paper. But in practice?
- 40%+ of events never get used
- Identity graphs often duplicate across tools
- You’re paying for features you don't need
Just because it integrates everything doesn’t mean it improves performance.
Warehouse-First Is Now the Default for Mid-Market
More mid-sized brands (especially DTC and SaaS) are going warehouse-first:
- Better data governance
- Cleaner LTV and churn modeling
- Fewer duplicate records across ESPs
In short: the warehouse is the source of truth, not your CDP.
When Reverse ETL Beats a CDP
If you need:
- AOV tiers for merch flows
- Churn scores for SaaS renewals
- Predicted SKUs for next-purchase offers
- Offline conversions for ad suppression
Reverse ETL is the better tool.
Native Integrations — Still Underrated
They may seem basic, but native tools can often deliver more than enough functionality—especially when paired with the right enhancements.
When Native Is Actually Enough
- Email-first companies (newsletters, ecomm)
- Shopify brands running Klaviyo flows
- B2B teams on HubSpot or Customer.io
If your use case is simple, this may be all you need.
Limitations to Watch For
- No strong schema enforcement
- Hard to enrich profiles
- Weak identity stitching
But for early-stage teams, those tradeoffs are acceptable.
How Native + Reverse ETL Work Together
Use both:
- Native for basic flows (e.g., email opened, cart added)
- Reverse ETL for layered enrichment (e.g., segmentation score, predicted churn)
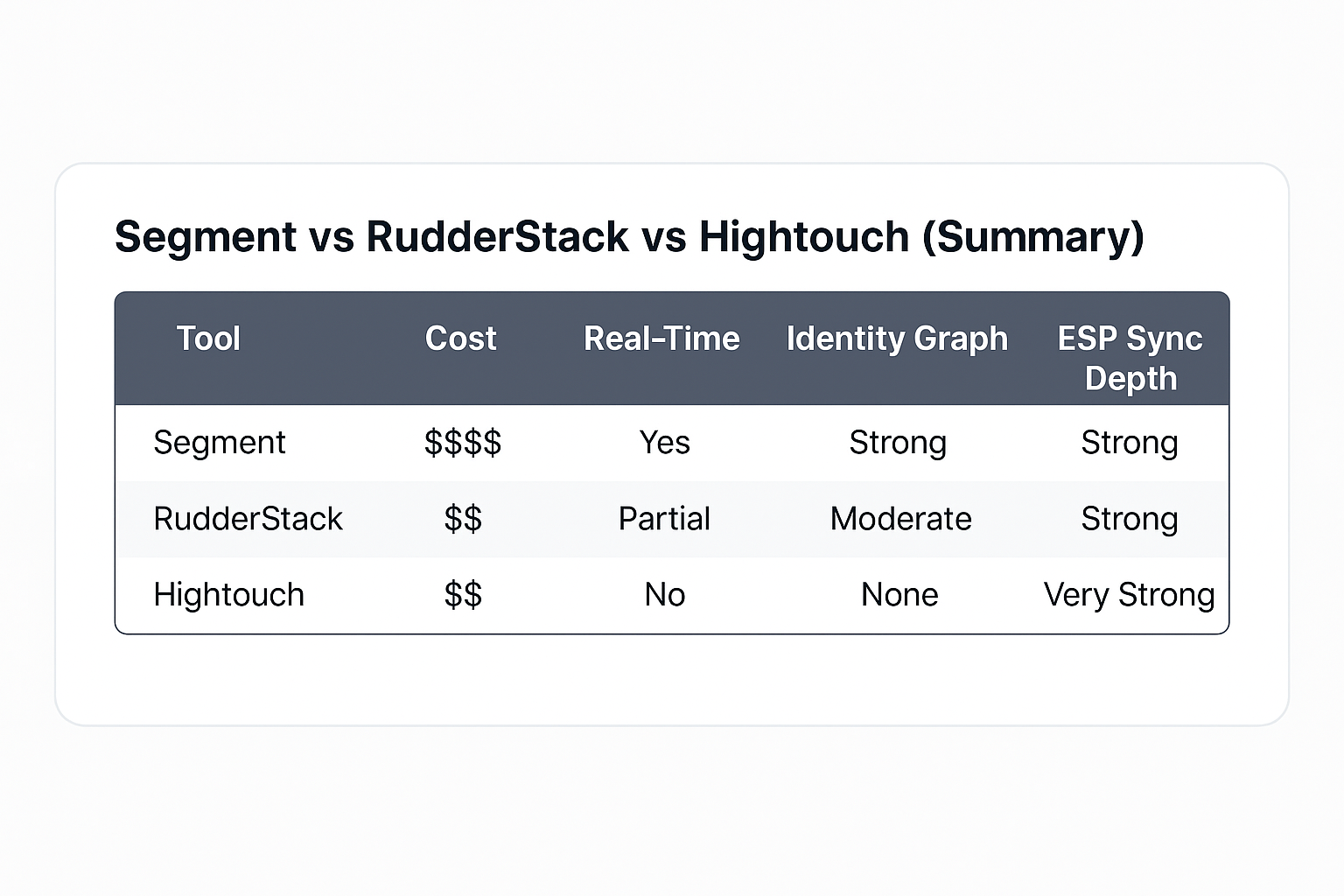
Deep Dive: RudderStack vs Segment vs Hightouch
These three tools dominate the data activation conversation. But they serve different roles. Here's a real comparison—without the vendor pitch deck.
Segment
- Enterprise-scale, real-time, broadest integration library
- Most expensive
- Best for teams doing heavy streaming (mobile/web)
RudderStack
- Warehouse-native (syncs with Snowflake/BigQuery)
- Lower cost than Segment
- Easier for engineers to adopt
Hightouch
- Not a CDP, but strong enough to replace one in many stacks
- Deep Reverse ETL capabilities
- Best-in-class ESP syncs
Decision Tree Walkthrough — 3 Real-World Scenarios
Sometimes it's easier to learn by example. Here are three company profiles—and how each should approach their integration strategy.
Scenario 1 — DTC Brand on Shopify + Klaviyo
Solution: Native + Reverse ETL
Why: Simple behavior events via Shopify. Model churn + LTV in warehouse and push via Hightouch.
Scenario 2 — SaaS Company with Complex Usage Data
Solution: Warehouse + Reverse ETL
Why: Product analytics drives churn prevention, onboarding nudges, expansion targeting. Needs warehouse modeling.
Scenario 3 — Multi-Brand Marketplace
Solution: CDP (Segment or RudderStack)
Why: Complex identity resolution, device matching, cross-brand deduplication
Operational Considerations (The Stuff Vendors Don’t Tell You)
Beyond features and pricing, there are real ownership and risk factors at play. Don’t ignore these behind-the-scenes truths.
Cost Modeling
- CDP: priced by MTUs/events, gets expensive fast
- Reverse ETL: priced by syncs or rows, generally flat
- Warehouse: compute + storage based; scales predictably
Data Ownership
- Who defines schemas?
- Who owns the ID map?
- Who handles user consent?
In CDPs, it’s shared. In warehouse setups, it’s yours.
Vendor Lock-In Risks
- CDP: High
- Reverse ETL: Medium
- Native: Low
Final Framework — A Simple “Middle Layer” Selection Matrix
Still unsure? Here’s a boiled-down version of the tradeoffs—based on volume, maturity, and how much real-time power you actually need.
Data volume
- Native: Low
- Reverse ETL: Medium
- CDP: High
Team maturity
- Native: Low
- Reverse ETL: Medium
- CDP: High
Real-time needs
- Native: No
- Reverse ETL: Partial
- CDP: Yes
Budget sensitivity
- Native: High
- Reverse ETL: Medium
- CDP: Low
Privacy/SLA needs
- Native: Basic
- Reverse ETL: Moderate
- CDP: Complex
Cross-system sync
- Native: Minimal
- Reverse ETL: Precise
- CDP: Unified
Conclusion — Pick the Leanest Middle Layer That Gets the Job Done
You don’t need to spend big to build smart. Match your tools to your stage, not your aspirations—and you’ll move faster with less waste.
Here’s the truth:
- Don’t overbuy CDPs for features you won't use
- Don’t overengineer Reverse ETL without a strong warehouse base
- Don’t ignore native integrations just because they sound "basic"
- Make the warehouse your control plane
Need help architecting your stack?
Get an unbiased review from Wired Messenger.